





A Corpus of Irish English
In the following the structure and design of A Corpus of Irish English is described. The corpus gathers together the main documents for the English language in Ireland throughout its history. These begin in the early fourteenth century and continue up to the present-day. There are various genres represented in the corpus, reflecting the diversity of text types to be found in the history of Irish English: poetry, glossaries, sketches and full-length plays. The material has been arranged so as to be displayed in an intuitive fashion within Corpus Presenter, a program suite by the present author with which you can examine the files of A Corpus of Irish English. With Corpus Presenter you can browse through the files of the corpus by just clicking on the nodes of the tree you are presented with. You can also, of course, begin working straight away and carry out retrieval tasks concerning matters of interest to you within the context of Irish English.
A Corpus of Irish English was published with Corpus Presenter by John Benjamins, Amsterdam in 2003, see Information on Corpus Presenter. There is an update for the Corpus Presenter program suite (Version 2026, Build: 2.0, March 2026) which is available on the author’s homepage (go to node Corpus Presenter under Recent book projects).

Getting started
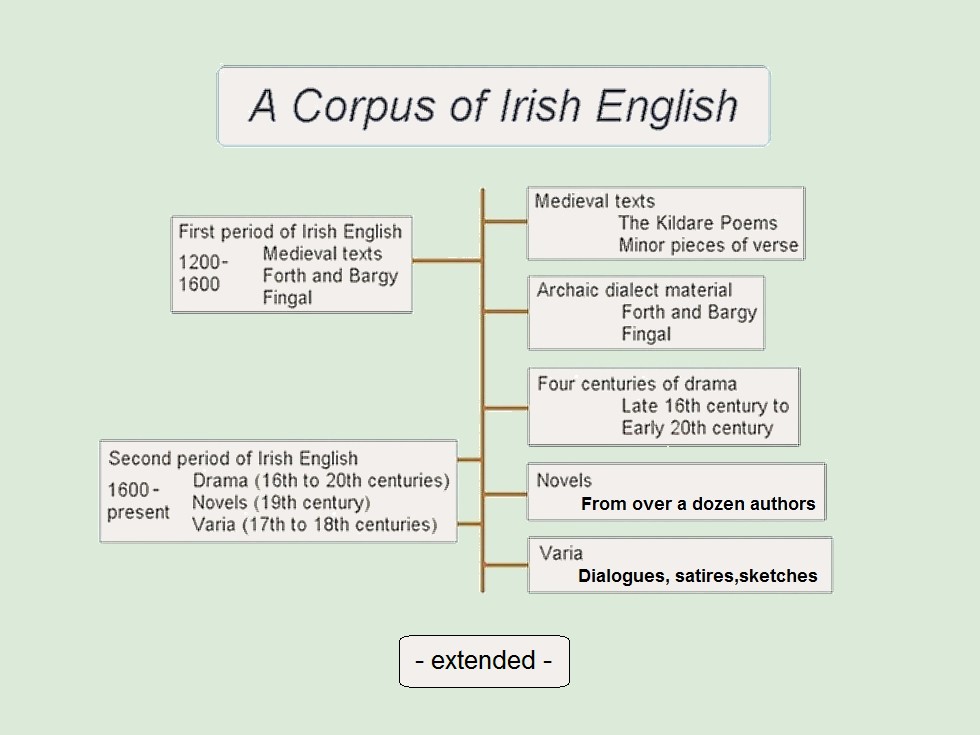
A Corpus of Irish English consists of over 120 texts with a time span of nearly 600 years. The material is arranged in a manner which reflects the main division in the history of Irish English into an earlier period, from the late twelfth century to the end of the sixteenth century, and a later period, from the beginning of the seventeenth century to the present. The beginning of the first period is marked by the Norman invasion of 1169 and ends with the defeat of the Irish forces at the battle of Kinsale in 1601. After that date a renewed plantation of the country began with vigorous policies being applied throughout the seventeenth century which led to new forms of English being introduced, both to the north (from Lowland Scotland) and the south (from Western and North-Western England). There is a degree of continuity between the two periods in the east coast, above all in the city of Dublin. For the remainder of the country the English of the early modern period (seventeenth century) formed the basis for later developments.
First period of Irish English |
Second period of Irish English |
Middle Ages |
Drama (sixteenth to twentieth centuries) |
Forth and Bargy |
Novels (nineteenth century) |
Fingal |
Varia (seventeenth to eighteenth centuries) |
Sources of the corpus texts
There are basically two sources for the texts of A Corpus of Irish English. The first consists of Irish writers using English as their literary medium. This is the case with the Kildare Poems which represent the earliest attestations of Irish English. Whether these authors were native speakers of Irish, English or to some degree bilingual is uncertain. What is true is that they knew the form of English in Ireland from first hand. The second source consists of writers from outside Ireland, for all practical purposes from England, who chose to represent Irish English in their works, mainly with the aim literary parody, i.e. often within the context of the stage Irishman, a stock figure of fun in English drama.
As the documents stem from both Irish-born and English-born writers they represent a perspective from within and without so to speak. Linguistically this fact is particularly interesting as it tells us what features of earlier Irish English were salient and hence perceived by English authors concerned with imitating Irish speech in their writings. This situation applied from the time of Shakespeare until well into the nineteenth century and has to a certain extent not ceased to exist if one takes more modern media, apart from drama, into account.
Text types in the corpus
The range of text types in the history of Irish English is impressive. It starts with poetry, the so-called Kildare Poems, a collection of 16 poems in the Harley 931 manuscript housed in the British Museum. There are glossaries for the dialect of Forth and Bargy from the late eighteenth and early nineteenth century. These are stored in A Corpus of Irish English as databases and can be transferred to text if you wish. The two remaining text types are 1) drama and 2) the novel. In the latter case one complete novel has been included, Castle Rackrent by Maria Edgeworth, because of its importance as the first regional novel in Britain and because in it the author represents the speech of the Irish population as we presume she would have heard it. The plays contained in the corpus cover a time span of some four centuries, starting with some pieces from the Elizabethan era, through the Restoration period and into the nineteenth and early twentieth centuries. Given the speech basis of drama it plays a central role in the documentation of historical Irish English and is hence so amply represented in A Corpus of Irish English.
Retrieving information
As you are reading this text it can be assumed that you succeeded in installing both the Corpus Presenter and A Corpus of Irish English. The corpus can be surveyed by clicking on the nodes of the tree which is displayed on the left. Apart from simply browsing in the corpus you will obviously wish to extract information from the texts it contains. This is done by moving to the retrieval level of Corpus Presenter. You press Ctrl-L or click on the binocular button on the tool bar at the top of the screen and then you choose to specify parameters for a search. What Corpus Presenter will now do is to comb through as many texts as you select and look for the information you specify. For instance, if you wish to search for a syntactic construction, say the habitual aspect in Irish English, then you would enter a search string do – or a list consisting of all the forms of do you would expect – and another string be so that the program would return finds like ...does ...be ... or ...do...be..., etc. Another example would be the immediate perfective of Irish English. Here you would enter after as search string 1 and ing as search string 2 and specify that string 1 is an entire word and string 2 only a part and in addition must occur at the end of a word. This will then lead to returns like She´s after selling the house. They´re after burning the wood., etc.
The search parameters levels contains many useful options. For instance you might wish to specify that only a certain number of intervening items can occur between string 1 and 2, or that a sentence boundary should not be allowed between the two strings. Furthermore you might wish to have the whole sentence returned as the context for a find. All these and many other options are available here so make sure that you try out all of them to recognise how they might be useful for you in your retrieval tasks.
All the parameters you may have specified for a certain search can be saved to disk. The suggested extension for a search profile file on disk is .SPR which you are advised to keep to in order to recognise such a file in future.
Search returns
There are a number of ways for Corpus Presenter to deposit returns from a retrieval run. The simplest is as a plain text which can be copied directly via the normal Cut and Paste keys of Windows. The next is as a line list which is slightly more structured in that each return occupies a separate line in the list. The most flexible type of output for retrieval returns is doubtlessly a grid. This is a lattice of rows and columns. There is one row per find. The number of columns depends on the settings for the parameters activated by clicking on the button Grid options (see next two options for details).
Multi-line grid This type of return repository allows for the context to contain more than one line. For instance, you might find it useful to have several lines before and after the find for a string or strings. This is possible with the current option. There is one important restriction, however: a multi-line grid cannot be saved as a database as the fields of a database can only accept single lines of text.
Possible columns Apart from the column Text section, which is obligatory and which cannot be unchecked, there are a number of other columns which you can add to an multi-line grid by checking them. The columns Location, File name, Node label will include the numeric position of a find in a text, the name of the text file from which it derives and the label for the node in the tree which it occupies. In addition you can add up to 4 user columns. Here you can enter information which you might want to add to that automatically returned by Corpus Presenter.
Marking rows in grids In both the multi-line and the single-line grids you can mark rows discontinuously by holding down the Control key and clicking on a row with the left mouse button. Bear in mind that selected rows can be copied to text at any time by choosing the option Copy to text window which is visible after a set of returns are displayed on this level.
Editing options When you edit a cell in a multi-line grid you will notice that a button appears in the top right-hand corner. If you click this the macro window (see 5.1 Edit text macros below) appears and you can edit a stretch of text, store the macros to disk, load a new file, etc. If you choose to insert the current macro line into the present cell then this is added to the contents of the cell (with a new line before it). You may also insert the current date or time into a cell.
Single-line grid Here only the amount of a context back to the last line break and forward to the next is returned along with the search string with a positive find. These returns can be used as the input to a database directly, for instance you could process the results with Corpus Presenter Database Manager, see below.
Possible columns Apart from the column Keyword which is obligatory and which cannot be unchecked, there are a number of others which you can insert for a single-line grid by checking them. The left and right flank (trimmed, i.e. with trailing or preceding blanks removed, or not) for a find can be included and you can specify whether the delimiters, set in the main search parameters window, should also be included. The columns Location, File name, Node label will include the numeric position of a find in a text, the name of the text file from which it derives and the label for the node in the tree which it occupies. In addition you can add 1 or 2 user columns. Here you can enter information which you might want to add to that automatically returned by Corpus Presenter.
Sorting a single-line grid One inherent advantage of the single-line grid is that it allows one to sort any field in either ascending or descending order. All you do is click on a column heading and the entire grid is sorted according to this column. The sort option is a toggle: clicking a heading once will lead to an ascending sort on that column, clicking again will cause the field to be sorted in descending order.
Separators between output fields There are different ways of separating the fields for each return (assuming that the repository type is a text). Four common options are offered here, along with the choice of having no separator. These various types are a matter of personal taste; it is best just to try them out and see how you find them.
Output file in Corpus Presenter Table Editor format There is a supplied program for editing tables generated by Corpus Presenter, see the description of Corpus Presenter Table Editor below. If you choose to save returns in this format then you can edit these separately with the table editor and export them from there to a text editor. One of the advantages of this is that the table editor can handle several tables at once, so that if you have several return sets you can edit these as a group later independently from Corpus Presenter.
Output returns as text table The results of a retrieval run can be transferred to a text table in the internal editor of Corpus Presenter (here the editor is called a jotter as you can use it to take notes during a work session). All you need to do is to choose the option Export to RTF text table in the Returns menu. Assuming that you have collected returns in a multi-line grid, they are now copied to a table which has the same proportions as the source grid. Additionally, before carrying out this step, you can specify that only a subset of rows (those currently selected) and/or only the visible columns of the grid are exported.
Range of searches
As A Corpus of Irish English consists of different files from various periods and representing many genres then you may very well not wish to run retrieval tasks on all files. There are two ways of ensuring this. The first is somewhat more complicated but can be useful. This is to create a sub-corpus by checking files in the list mode and then exporting them as a new corpus to a different folder. The second method is easier and more likely to be employed regularly. This is to specify a certain range for the search. Basically, there are five possible types: 1) From first file, 2) Branch only, 3) Just current text, 4) From current position to end, 5) Checked files. The first three options refer to a section of the tree on the left of the screen, i.e. the entire tree, a branch or a single node. But there are cases where the files to be encompassed cannot be referenced by a section of a tree. In such cases what one does is to change the tree display to a list-type display (this can be done via the option Tree or list display in the Display menu, shortcut: F11). Now you can check files of your corpus as you wish. When the selection is made you move to the retrieval level or activate the word list window (depending on the impending task) and proceed.
Making word lists The idea behind this option is to allow users to generate lists of words from the text files of a corpus. At a maximum, you can create a word list of all words in all text files of a corpus. This would take many hours for a large corpus and is unlikely to be the aim of most users, but can be done of course. Instead what linguists are probably interested in is in creating a list of selected words in a corpus. For this reason, one of the first options in the large input window which opens on selecting this command is Input word list. Here you specify a plain ASCII file which consists of a list of words, one on each line. Such a word list can be easily be created with the supplied text Corpus Presenter Text Editor. The next item to remember, and which is concerned with restricting the words used for a list, is a stop word list. Essentially, this is a list of words (again in the form of a plain ASCII file) which are to be excluded from word list generation. For instance, if you choose to make a word list of an entire text, then it is unlikely that you want to have statistics on the occurrence of such common formatives as a, the, on, at, etc. These and similar words can be excluded by putting them into a stop words list and then specifying it on this level of the program.
Word lists can be saved to disk as a text file or as a database. The latter file format is much more flexible and allows for flexible processing of the data it contains subsequently. However, it does require that users concern themselves with database organisation and manipulation.
Corpus Presenter