




 Helsinki Corpus Files (size: 91 KB)
Helsinki Corpus Files (size: 91 KB)
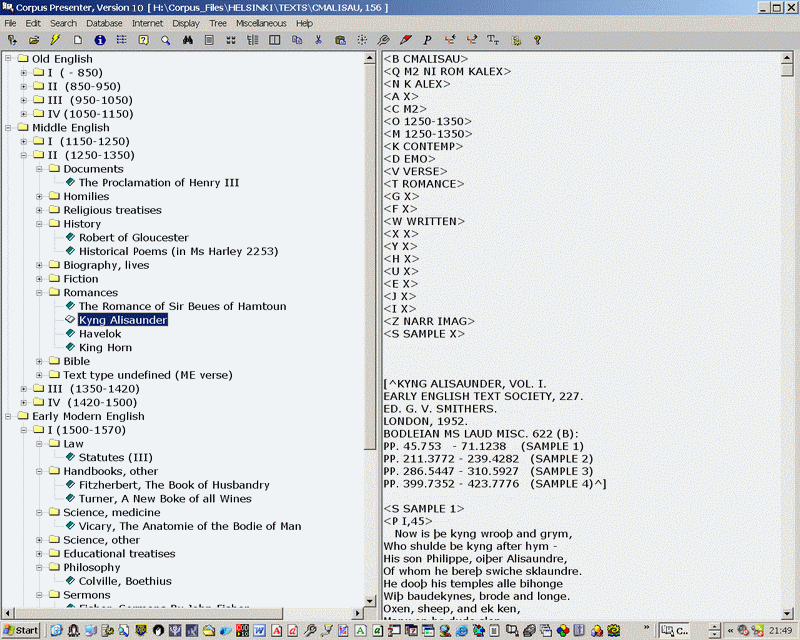
The Helsinki Corpus of English Texts consists of 242 text files which are located in a single directory. I have constructed a data set file – Helsinki_Corpus.cpd – which will display the Helsinki Corpus as a hierarchical tree divided into layers according to period (Old, Middle and Early Modern English) and sub-period and then by genre as can be seen in the following screen shot.

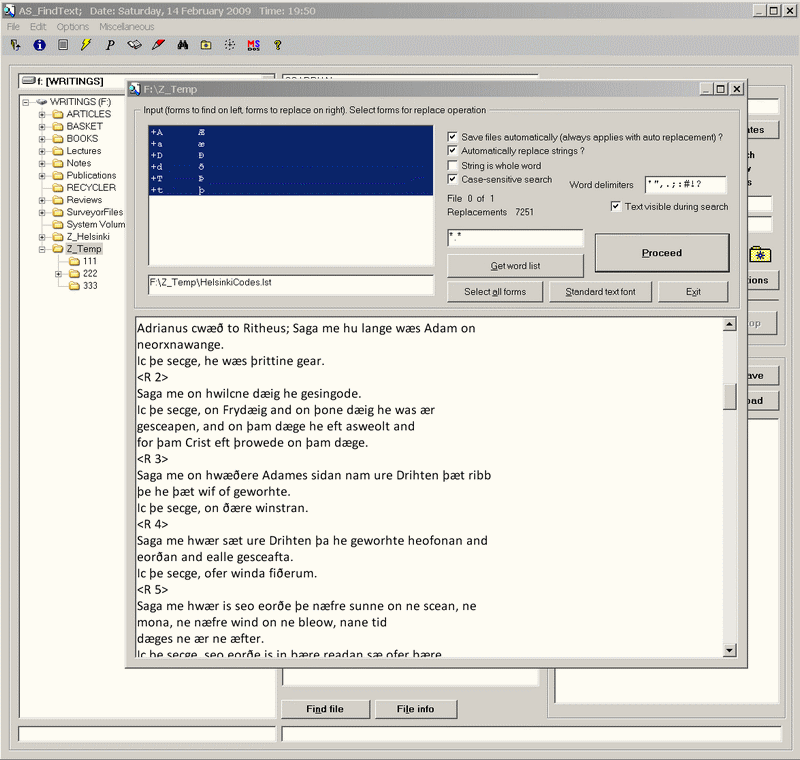
The second file is intended for use with the supplied utility Corpus Presenter Find Text. The file is Helsinki_Codes.lst and it will replace the sequences of "+" and a letter with the actual Old and Middle English symbols, ash, thorn and eth in all the texts of the corpus which contain these. This makes the Old and Middle English texts much more readable. Bear in mind that the symbols, ash, thorn and eth can be accessed in Corpus Presenter modules by clicking on the button OE/ME, e.g. in the search options window of the Quick search or the parameters window on the Advanced search level.
To carry out the replacements, do the following. Unzip the download file Helsinki.zip from the above link to the directory in which you keep the files of the Helsinki Corpus. Start Corpus Presenter Find Text and enter this directory. Choose Helsinki_Codes.lst as the file with input form for the Find / Replace operation. Select all the forms and click on the Proceed button. When the files have been processed, all replacements will have been made. The procedure should take some minutes, that is normal.
The problem of yogh
In the ZIP file Helsinki.zip there is another file for doing replacements in Helsinki Corpus texts, namely Helsinki_Codes_with_Yogh.lst. The following additional lines can be found in this file:
+g 3
+G 3
These replace all instances of +g and +G, the representation of yogh in the Helsinki Corpus texts, with the number 3 (there are no separate uppercase and lowercase forms for Arabic numerals, hence the same replacement in both cases). The only problem here is that earlier English yogh is not really a 3 (the number ‘three’). If you do carry out this replacement in the Helsinki Corpus texts, then you will have to remember to enter 3 every time you search for a string in Corpus Presenter which has yogh (= 3) in it. You can do that, it’s messy I admit, but it is a solution because 3 instead of +g is definitely makes texts more readable.
There are two further data set files in the ZIP file Helsinki.zip: (1) CEECS.cpd which is designed to work with the Corpus of Early English Correspondence Sampler by Terttu Nevalainen and Helena Raumolin-Brunberg, (2) Old_Scots.cpd which can be used with the Helsinki Corpus of Older Scots by Anneli Meurman-Solin.