




 A Corpus of Irish English (extended, c. 20 MB Zip file)
A Corpus of Irish English (extended, c. 20 MB Zip file)
|
In the following the structure and design of A Corpus of Irish English is described. The corpus gathers together the main documents for the English language in Ireland throughout its history. These begin in the early 14th century and continue up to the present-day. There are various genres represented in the corpus, reflecting the diversity of text types to be found in the history of Irish English: poetry, glossaries, sketches and full-length plays along with stories and novels. The material has been arranged so as to be displayed in an intuitive fashion within Corpus Presenter with which you can examine the files of A Corpus of Irish English. Corpus Presenter lets you browse through the files of the corpus by just clicking on the nodes of the tree you are presented with. You can also, of course, begin working straight away and carry out retrieval tasks concerning matters of interest to you within the context of Irish English.
A Corpus of Irish English was published with Corpus Presenter by John Benjamins, Amsterdam in 2003. The present version, which can be downloaded from the link above has been extended, above all by the addition of nineteenth century material, chiefly novels by Irish authors. The descriptions below assume that you are viewing the corpus with Corpus Presenter.

Getting started
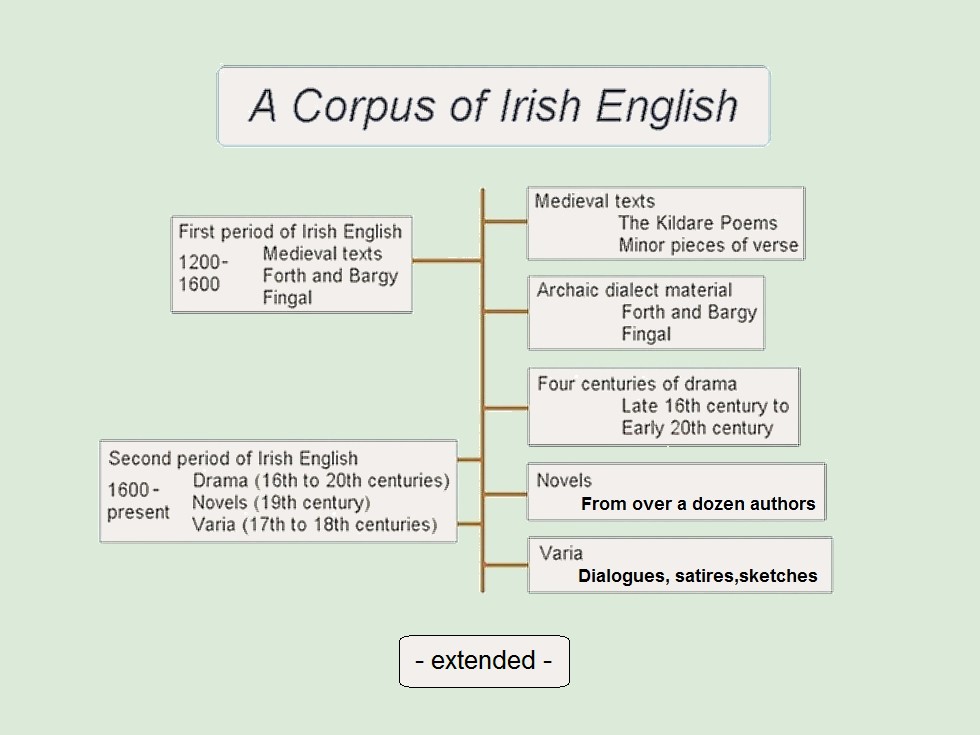
First period of Irish English |
Second period of Irish English |
Middle Ages |
Drama (16th to 20th centuries) |
Forth and Bargy |
Novels (19th and 20th centuries) |
Fingal |
Varia (17th to 18th centuries) |
Sources of the corpus texts
There are basically two sources for the texts of A Corpus of Irish English. The first consists of Irish writers using English as their literary medium. This is the case with the Kildare Poems which represent the earliest attestations of Irish English. Whether these authors were native speakers of Irish, English or to some degree bilingual is uncertain. What is true is that they knew the form of English in Ireland from first hand. The second source consists of writers from outside Ireland, for all practical purposes from England, who chose to represent Irish English in their works, mainly with the aim literary parody, i.e. often within the context of the stage Irishman, a stock figure of fun in English drama.
As the documents stem from both Irish-born and English-born writers they represent a perspective from within and without so to speak. Linguistically this fact is particularly interesting as it tells us what features of earlier Irish English were salient and hence perceived by English authors concerned with imitating Irish speech in their writings. This situation applied from the time of Shakespeare until well into the 19th century and has to a certain extent not ceased to exist if one takes more modern media, apart from drama, into account.
Text types in the corpus
Retrieving information
The search parameters level contains many useful options. For instance you might wish to specify that only a certain number of intervening items can occur between string 1 and 2, or that a sentence boundary should not be allowed between the two strings. Furthermore, you might wish to have the whole sentence returned as the context for a find. All these and many other options are available here so make sure that you try out all of them to recognise how they might be useful for you in your retrieval tasks.
All the parameters you may have specified for a certain search can be saved to disk. The suggested extension for a search profile file on disk is .CFG (= ‘configuation’) which you are advised to keep to in order to recognise such a file in future.
Range of searches
As A Corpus of Irish English consists of different files from various periods and representing many genres you may very well not wish to run retrieval tasks on all files. There are two ways of ensuring this. The first is somewhat more complicated but can be useful. This is to create a sub-corpus by checking files in the list mode and then exporting them as a new corpus to a different folder. The second method is easier and more likely to be employed regularly. This is to specify a certain range for the search. Basically, there are five possible types: 1) From first file, 2) Branch only, 3) Just current text, 4) From current position to end, 5) Checked files. The first three options refer to a section of the tree on the left of the screen, i.e. the entire tree, a branch or a single node. But there are cases where the files to be encompassed cannot be referenced by a section of a tree. In such cases what one does is to change the tree display to a list-type display (this can be done via the option Tree or list display in the Display menu, shortcut: F11). Now you can check files of your corpus as you wish. When the selection is made you move to the retrieval level or activate the word list window (depending on the impending task) and proceed.
Making word lists
This option allows users to generate lists of words from the text files of a corpus. At a maximum, you can create a word list of all words in all text files of a corpus. This is unlikely to be the aim of most users, but can be done of course. Instead what linguists are probably interested in is to create a list of selected words in a corpus. For this reason, one of the first options in the large input window which opens on selecting this command is Input word list. Here you specify a plain ASCII file which consists of a list of words, one on each line. Such a word list can be easily created with the supplied program Corpus Presenter Text Editor. The next item to remember, and which is concerned with restricting the words used for a list, is a stop word list. Essentially, this is a list of words (again in the form of a plain ASCII file) which are to be excluded from word list generation. For instance, if you choose to make a word list of an entire text, then it is unlikely that you want to have statistics on the occurrence of such common formatives as a, the, on, at, etc. These and similar words can be excluded by putting them into a stop words list and then specifying it on this level of the program. Word lists can be saved to disk as a text file, a database, a HTML file or an Excel spreadsheet. The latter file format is suitable for further processing of data by different software as most programs for statistical work can take data in Excel files as input.